docker网络
本文共 16005 字,大约阅读时间需要 53 分钟。
Docker作为目前最火的轻量级容器技术,牛逼的功能,如Docker的镜像管理,不足的地方网络方面。
Docker自身的4种网络工作方式,和一些自定义网络模式 安装Docker时,它会自动创建三个网络,bridge(创建容器默认连接到此网络)、 none 、host host:容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。 Container:创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围。 None:该模式关闭了容器的网络功能。 Bridge:此模式会为每一个容器分配、设置IP等,并将容器连接到一个docker0虚拟网桥,通过docker0网桥以及Iptables nat表配置与宿主机通信。 以上都是不用动手的,真正需要配置的是自定义网络。一、前言
本文首先介绍了Docker自身的4种网络工作方式,然后介绍一些自定义网络模式。二、默认网络
当你安装Docker时,它会自动创建三个网络。你可以使用以下docker network ls命令列出这些网络: $ docker network ls NETWORK ID NAME DRIVER 7fca4eb8c647 bridge bridge 9f904ee27bf5 none null cf03ee007fb4 host host Docker内置这三个网络,运行容器时,你可以使用该–network标志来指定容器应连接到哪些网络。 该bridge网络代表docker0所有Docker安装中存在的网络。除非你使用该docker run --network=选项指定,否则Docker守护程序默认将容器连接到此网络。 我们在使用docker run创建Docker容器时,可以用 --net 选项指定容器的网络模式,Docker可以有以下4种网络模式: host模式:使用 --net=host 指定。 none模式:使用 --net=none 指定。 bridge模式:使用 --net=bridge 指定,默认设置。 container模式:使用 --net=container:NAME_or_ID 指定。 下面分别介绍一下Docker的各个网络模式。 2.1 Host 相当于Vmware中的桥接模式,与宿主机在同一个网络中,但没有独立IP地址。众所周知,Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等。一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable规则等都与其他的Network Namespace隔离。一个Docker容器一般会分配一个独立的Network Namespace。但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。 例如,我们在10.10.0.186/24的机器上用host模式启动一个含有nginx应用的Docker容器,监听tcp80端口。运行容器;
$ docker run --name=nginx_host --net=host -p 80:80 -d nginx
74c911272942841875f4faf2aca02e3814035c900840d11e3f141fbaa884ae5c查看容器;
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 74c911272942 nginx “nginx -g 'daemon …” 25 seconds ago Up 25 seconds nginx_host 当我们在容器中执行任何类似ifconfig命令查看网络环境时,看到的都是宿主机上的信息。而外界访问容器中的应用,则直接使用10.10.0.186:80即可,不用任何NAT转换,就如直接跑在宿主机中一样。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。 1 2 $ netstat -nplt | grep nginx tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 27340/nginx: master 2.2 Container 在理解了host模式后,这个模式也就好理解了。这个模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。 2.3 None 该模式将容器放置在它自己的网络栈中,但是并不进行任何配置。实际上,该模式关闭了容器的网络功能,在以下两种情况下是有用的:容器并不需要网络(例如只需要写磁盘卷的批处理任务)。 overlay 在docker1.7代码进行了重构,单独把网络部分独立出来编写,所以在docker1.8新加入的一个overlay网络模式。Docker对于网络访问的控制也是在逐渐完善的。 2.4 Bridge 相当于Vmware中的Nat模式,容器使用独立network Namespace,并连接到docker0虚拟网卡(默认模式)。通过docker0网桥以及Iptables nat表配置与宿主机通信;bridge模式是Docker默认的网络设置,此模式会为每一个容器分配Network Namespace、设置IP等,并将一个主机上的Docker容器连接到一个虚拟网桥上。下面着重介绍一下此模式。三、Bridge模式
3.1 Bridge模式的拓扑 当Docker server启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。接下来就要为容器分配IP了,Docker会从RFC1918所定义的私有IP网段中,选择一个和宿主机不同的IP地址和子网分配给docker0,连接到docker0的容器就从这个子网中选择一个未占用的IP使用。如一般Docker会使用172.17.0.0/16这个网段,并将172.17.0.1/16分配给docker0网桥(在主机上使用ifconfig命令是可以看到docker0的,可以认为它是网桥的管理接口,在宿主机上作为一块虚拟网卡使用)。单机环境下的网络拓扑如下,主机地址为10.10.0.186/24。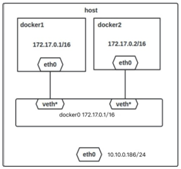
- 在主机上创建一对虚拟网卡veth pair设备。veth设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。因此,veth设备常用来连接两个网络设备。
- Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0。另一端放在主机中,以veth65f9这样类似的名字命名,并将这个网络设备加入到docker0网桥中,可以通过brctl show命令查看。 $ brctl show bridge name bridge id STP enabled interfaces docker0 8000.02425f21c208 no
- 从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。
运行容器;
$ docker run --name=nginx_bridge --net=bridge -p 80:80 -d nginx
9582dbec7981085ab1f159edcc4bf35e2ee8d5a03984d214bce32a30eab4921a查看容器;
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9582dbec7981 nginx “nginx -g 'daemon …” 3 seconds ago Up 2 seconds 0.0.0.0:80->80/tcp nginx_bridge查看容器网络;
$ docker inspect 9582dbec7981
“Networks”: { “bridge”: { “IPAMConfig”: null, “Links”: null, “Aliases”: null, “NetworkID”: “9e017f5d4724039f24acc8aec634c8d2af3a9024f67585fce0a0d2b3cb470059”, “EndpointID”: “81b94c1b57de26f9c6690942cd78689041d6c27a564e079d7b1f603ecc104b3b”, “Gateway”: “172.17.0.1”, “IPAddress”: “172.17.0.2”, “IPPrefixLen”: 16, “IPv6Gateway”: “”, “GlobalIPv6Address”: “”, “GlobalIPv6PrefixLen”: 0, “MacAddress”: “02:42:ac:11:00:02” } }$ docker network inspect bridge
[
{ “Name”: “bridge”, “Id”: “9e017f5d4724039f24acc8aec634c8d2af3a9024f67585fce0a0d2b3cb470059”, “Created”: “2017-08-09T23:20:28.061678042-04:00”, “Scope”: “local”, “Driver”: “bridge”, “EnableIPv6”: false, “IPAM”: { “Driver”: “default”, “Options”: null, “Config”: [ { “Subnet”: “172.17.0.0/16” } ] }, “Internal”: false, “Attachable”: false, “Ingress”: false, “Containers”: { “9582dbec7981085ab1f159edcc4bf35e2ee8d5a03984d214bce32a30eab4921a”: { “Name”: “nginx_bridge”, “EndpointID”: “81b94c1b57de26f9c6690942cd78689041d6c27a564e079d7b1f603ecc104b3b”, “MacAddress”: “02:42:ac:11:00:02”, “IPv4Address”: “172.17.0.2/16”, “IPv6Address”: “” } }, “Options”: { “com.docker.network.bridge.default_bridge”: “true”, “com.docker.network.bridge.enable_icc”: “true”, “com.docker.network.bridge.enable_ip_masquerade”: “true”, “com.docker.network.bridge.host_binding_ipv4”: “0.0.0.0”, “”: “docker0”, “com.docker.network.driver.mtu”: “1500” }, “Labels”: {} } ] 网络拓扑介绍完后,接着介绍一下bridge模式下容器是如何通信的。 3.3 bridge模式下容器的通信 在bridge模式下,连在同一网桥上的容器可以相互通信(若出于安全考虑,也可以禁止它们之间通信,方法是在DOCKER_OPTS变量中设置–icc=false,这样只有使用–link才能使两个容器通信)。 Docker可以开启容器间通信(意味着默认配置–icc=true),也就是说,宿主机上的所有容器可以不受任何限制地相互通信,这可能导致拒绝服务攻击。进一步地,Docker可以通过–ip_forward和–iptables两个选项控制容器间、容器和外部世界的通信。 容器也可以与外部通信,我们看一下主机上的Iptable规则,可以看到这么一条 1 -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE 这条规则会将源地址为172.17.0.0/16的包(也就是从Docker容器产生的包),并且不是从docker0网卡发出的,进行源地址转换,转换成主机网卡的地址。这么说可能不太好理解,举一个例子说明一下。假设主机有一块网卡为eth0,IP地址为10.10.101.105/24,网关为10.10.101.254。从主机上一个IP为172.17.0.1/16的容器中ping百度(180.76.3.151)。IP包首先从容器发往自己的默认网关docker0,包到达docker0后,也就到达了主机上。然后会查询主机的路由表,发现包应该从主机的eth0发往主机的网关10.10.105.254/24。接着包会转发给eth0,并从eth0发出去(主机的ip_forward转发应该已经打开)。这时候,上面的Iptable规则就会起作用,对包做SNAT转换,将源地址换为eth0的地址。这样,在外界看来,这个包就是从10.10.101.105上发出来的,Docker容器对外是不可见的。 那么,外面的机器是如何访问Docker容器的服务呢?我们首先用下面命令创建一个含有web应用的容器,将容器的80端口映射到主机的80端口。 1 $ docker run --name=nginx_bridge --net=bridge -p 80:80 -d nginx 然后查看Iptable规则的变化,发现多了这样一条规则: 1 -A DOCKER ! -i docker0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.17.0.2:80 此条规则就是对主机eth0收到的目的端口为80的tcp流量进行DNAT转换,将流量发往172.17.0.2:80,也就是我们上面创建的Docker容器。所以,外界只需访问10.10.101.105:80就可以访问到容器中的服务。 除此之外,我们还可以自定义Docker使用的IP地址、DNS等信息,甚至使用自己定义的网桥,但是其工作方式还是一样的。四、自定义网络
建议使用自定义的网桥来控制哪些容器可以相互通信,还可以自动DNS解析容器名称到IP地址。Docker提供了创建这些网络的默认网络驱动程序,你可以创建一个新的Bridge网络,Overlay或Macvlan网络。你还可以创建一个网络插件或远程网络进行完整的自定义和控制。 你可以根据需要创建任意数量的网络,并且可以在任何给定时间将容器连接到这些网络中的零个或多个网络。此外,您可以连接并断开网络中的运行容器,而无需重新启动容器。当容器连接到多个网络时,其外部连接通过第一个非内部网络以词法顺序提供。 接下来介绍Docker的内置网络驱动程序。 4.1 bridge 一个bridge网络是Docker中最常用的网络类型。桥接网络类似于默认bridge网络,但添加一些新功能并删除一些旧的能力。以下示例创建一些桥接网络,并对这些网络上的容器执行一些实验。 1 $ docker network create --driver bridge new_bridge 创建网络后,可以看到新增加了一个网桥(172.18.0.1)。 $ ifconfig br-f677ada3003c: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.18.0.1 netmask 255.255.0.0 broadcast 0.0.0.0 ether 02:42:2f:c1:db:5a txqueuelen 0 (Ethernet) RX packets 4001976 bytes 526995216 (502.5 MiB) RX errors 0 dropped 35 overruns 0 frame 0 TX packets 1424063 bytes 186928741 (178.2 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0 inet6 fe80::42:5fff:fe21:c208 prefixlen 64 scopeid 0x20 ether 02:42:5f:21:c2:08 txqueuelen 0 (Ethernet) RX packets 12 bytes 2132 (2.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 24 bytes 2633 (2.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 4.2 Macvlan Macvlan是一个新的尝试,是真正的网络虚拟化技术的转折点。Linux实现非常轻量级,因为与传统的Linux Bridge隔离相比,它们只是简单地与一个Linux以太网接口或子接口相关联,以实现网络之间的分离和与物理网络的连接。 Macvlan提供了许多独特的功能,并有充足的空间进一步创新与各种模式。这些方法的两个高级优点是绕过Linux网桥的正面性能以及移动部件少的简单性。删除传统上驻留在Docker主机NIC和容器接口之间的网桥留下了一个非常简单的设置,包括容器接口,直接连接到Docker主机接口。由于在这些情况下没有端口映射,因此可以轻松访问外部服务。 4.2.1 Macvlan Bridge模式示例用法 Macvlan Bridge模式每个容器都有唯一的MAC地址,用于跟踪Docker主机的MAC到端口映射。 Macvlan驱动程序网络连接到父Docker主机接口。示例是物理接口,例如eth0,用于802.1q VLAN标记的子接口eth0.10(.10代表VLAN 10)或甚至绑定的主机适配器,将两个以太网接口捆绑为单个逻辑接口。 指定的网关由网络基础设施提供的主机外部。 每个Macvlan Bridge模式的Docker网络彼此隔离,一次只能有一个网络连接到父节点。每个主机适配器有一个理论限制,每个主机适配器可以连接一个Docker网络。 同一子网内的任何容器都可以与没有网关的同一网络中的任何其他容器进行通信macvlan bridge。 相同的docker network命令适用于vlan驱动程序。 在Macvlan模式下,在两个网络/子网之间没有外部进程路由的情况下,单独网络上的容器无法互相访问。这也适用于同一码头网络内的多个子网。 在以下示例中,eth0在docker主机网络上具有IP地址172.16.86.0/24,默认网关为172.16.86.1,网关地址为外部路由器172.16.86.1。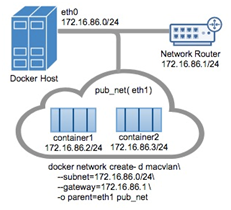
Macvlan (-o macvlan_mode= Defaults to Bridge mode if not specified)
docker network create -d macvlan
–subnet=172.16.86.0/24 –gateway=172.16.86.1 -o parent=eth0 pub_netRun a container on the new network specifying the --ip address.
docker run --net=pub_net --ip=172.16.86.10 -itd alpine /bin/sh
Start a second container and ping the first
docker run --net=pub_net -it --rm alpine /bin/sh
ping -c 4 172.16.86.10 看看容器ip和路由表: ip a show eth0 eth0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN link/ether 46:b2:6b:26:2f:69 brd ff:ff:ff:ff:ff:ff inet 172.16.86.2/24 scope global eth0ip route
default via 172.16.86.1 dev eth0 172.16.86.0/24 dev eth0 src 172.16.86.2NOTE: the containers can NOT ping the underlying host interfaces as
they are intentionally filtered by Linux for additional isolation.
In this case the containers cannot ping the -o parent=172.16.86.250
4.2.2 Macvlan 802.1q Trunk Bridge模式示例用法
VLAN(虚拟局域网)长期以来一直是虚拟化数据中心网络的主要手段,目前仍在几乎所有现有的网络中隔离广播的主要手段。 常用的VLAN划分方式是通过端口进行划分,尽管这种划分VLAN的方式设置比较很简单,但仅适用于终端设备物理位置比较固定的组网环境。随着移动办公的普及,终端设备可能不再通过固定端口接入交换机,这就会增加网络管理的工作量。比如,一个用户可能本次接入交换机的端口1,而下一次接入交换机的端口2,由于端口1和端口2属于不同的VLAN,若用户想要接入原来的VLAN中,网管就必须重新对交换机进行配置。显然,这种划分方式不适合那些需要频繁改变拓扑结构的网络。而MAC VLAN可以有效解决这个问题,它根据终端设备的MAC地址来划分VLAN。这样,即使用户改变了接入端口,也仍然处在原VLAN中。 Mac vlan不是以交换机端口来划分vlan。因此,一个交换机端口可以接受来自多个mac地址的数据。一个交换机端口要处理多个vlan的数据,则要设置trunk模式。 在主机上同时运行多个虚拟网络的要求是非常常见的。Linux网络长期以来一直支持VLAN标记,也称为标准802.1q,用于维护网络之间的数据路由隔离。连接到Docker主机的以太网链路可以配置为支持802.1q VLAN ID,方法是创建Linux子接口,每个子接口专用于唯一的VLAN ID。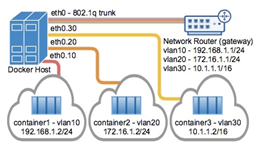
eth0.20: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
ether 00:0c:29:16:01:8b txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 在/proc/net/vlan/config文件中,还可以看见相关的Vlan信息,如下: $ cat /proc/net/vlan/config VLAN Dev name | VLAN ID Name-Type: VLAN_NAME_TYPE_RAW_PLUS_VID_NO_PAD eth0.10 | 10 | eth0 eth0.20 | 20 | eth0Docker的四种网络模式
Bridge模式 当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。 从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。 bridge模式是docker的默认网络模式,不写–net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。 bridge模式如下图所示: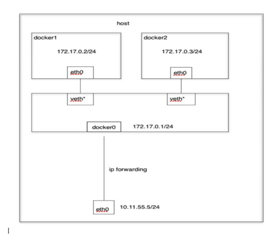 演示: #docker run -tid --net=bridge --name docker_bri1 ubuntu-base:v3 #docker run -tid --net=bridge --name docker_bri2 ubuntu-base:v3 #brctl show #docker exec -ti docker_bri1 /bin/bash #docker exec -ti docker_bri1 /bin/bash #ifconfig –a #route –n Host模式 如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。 Host模式如下图所示:
演示: #docker run -tid --net=bridge --name docker_bri1 ubuntu-base:v3 #docker run -tid --net=bridge --name docker_bri2 ubuntu-base:v3 #brctl show #docker exec -ti docker_bri1 /bin/bash #docker exec -ti docker_bri1 /bin/bash #ifconfig –a #route –n Host模式 如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。 Host模式如下图所示:  演示: #docker run -tid --net=host --name docker_host1 ubuntu-base:v3 #docker run -tid --net=host --name docker_host2 ubuntu-base:v3 #docker exec -ti docker_host1 /bin/bash #docker exec -ti docker_host1 /bin/bash #ifconfig –a #route –n Container模式 这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。 Container模式示意图:
演示: #docker run -tid --net=host --name docker_host1 ubuntu-base:v3 #docker run -tid --net=host --name docker_host2 ubuntu-base:v3 #docker exec -ti docker_host1 /bin/bash #docker exec -ti docker_host1 /bin/bash #ifconfig –a #route –n Container模式 这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。 Container模式示意图: 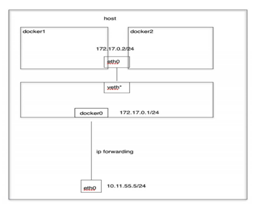 演示: #docker run -tid --net=container:docker_bri1 --name docker_con1 ubuntu-base:v3 #docker exec -ti docker_con1 /bin/bash #docker exec -ti docker_bri1 /bin/bash #ifconfig –a #route -n None模式 使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。 Node模式示意图:
演示: #docker run -tid --net=container:docker_bri1 --name docker_con1 ubuntu-base:v3 #docker exec -ti docker_con1 /bin/bash #docker exec -ti docker_bri1 /bin/bash #ifconfig –a #route -n None模式 使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。 Node模式示意图:  演示: #docker run -tid --net=none --name docker_non1 ubuntu-base:v3 #docker exec -ti docker_non1 /bin/bash #ifconfig –a #route -n 跨主机通信 Docker默认的网络环境下,单台主机上的Docker容器可以通过docker0网桥直接通信,而不同主机上的Docker容器之间只能通过在主机上做端口映射进行通信。这种端口映射方式对很多集群应用来说极不方便。如果能让Docker容器之间直接使用自己的IP地址进行通信,会解决很多问题。按实现原理可分别直接路由方式、桥接方式(如pipework)、Overlay隧道方式(如flannel、ovs+gre)等。 直接路由 通过在Docker主机上添加静态路由实现跨宿主机通信:
演示: #docker run -tid --net=none --name docker_non1 ubuntu-base:v3 #docker exec -ti docker_non1 /bin/bash #ifconfig –a #route -n 跨主机通信 Docker默认的网络环境下,单台主机上的Docker容器可以通过docker0网桥直接通信,而不同主机上的Docker容器之间只能通过在主机上做端口映射进行通信。这种端口映射方式对很多集群应用来说极不方便。如果能让Docker容器之间直接使用自己的IP地址进行通信,会解决很多问题。按实现原理可分别直接路由方式、桥接方式(如pipework)、Overlay隧道方式(如flannel、ovs+gre)等。 直接路由 通过在Docker主机上添加静态路由实现跨宿主机通信: 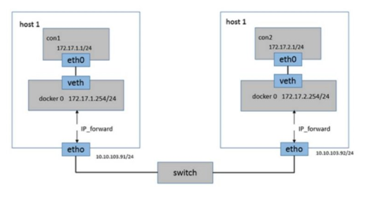 Pipework Pipework是一个简单易用的Docker容器网络配置工具。由200多行shell脚本实现。通过使用ip、brctl、ovs-vsctl等命令来为Docker容器配置自定义的网桥、网卡、路由等。 使用新建的bri0网桥代替缺省的docker0网桥 bri0网桥与缺省的docker0网桥的区别:bri0和主机eth0之间是veth pair
Pipework Pipework是一个简单易用的Docker容器网络配置工具。由200多行shell脚本实现。通过使用ip、brctl、ovs-vsctl等命令来为Docker容器配置自定义的网桥、网卡、路由等。 使用新建的bri0网桥代替缺省的docker0网桥 bri0网桥与缺省的docker0网桥的区别:bri0和主机eth0之间是veth pair 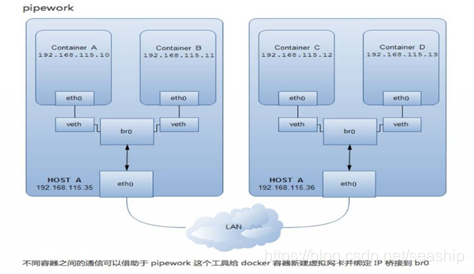 Flannel(Flannel + UDP 或者 Flannel + VxLAN) Flannel实现的容器的跨主机通信通过如下过程实现: 每个主机上安装并运行etcd和flannel; 在etcd中规划配置所有主机的docker0子网范围; 每个主机上的flanneld根据etcd中的配置,为本主机的docker0分配子网,保证所有主机上的docker0网段不重复,并将结果(即本主机上的docker0子网信息和本主机IP的对应关系)存入etcd库中,这样etcd库中就保存了所有主机上的docker子网信息和本主机IP的对应关系; 当需要与其他主机上的容器进行通信时,查找etcd数据库,找到目的容器的子网所对应的outip(目的宿主机的IP); 将原始数据包封装在VXLAN或UDP数据包中,IP层以outip为目的IP进行封装; 由于目的IP是宿主机IP,因此路由是可达的; VXLAN或UDP数据包到达目的宿主机解封装,解出原始数据包,最终到达目的容器。 Flannel模式如下图所示:
Flannel(Flannel + UDP 或者 Flannel + VxLAN) Flannel实现的容器的跨主机通信通过如下过程实现: 每个主机上安装并运行etcd和flannel; 在etcd中规划配置所有主机的docker0子网范围; 每个主机上的flanneld根据etcd中的配置,为本主机的docker0分配子网,保证所有主机上的docker0网段不重复,并将结果(即本主机上的docker0子网信息和本主机IP的对应关系)存入etcd库中,这样etcd库中就保存了所有主机上的docker子网信息和本主机IP的对应关系; 当需要与其他主机上的容器进行通信时,查找etcd数据库,找到目的容器的子网所对应的outip(目的宿主机的IP); 将原始数据包封装在VXLAN或UDP数据包中,IP层以outip为目的IP进行封装; 由于目的IP是宿主机IP,因此路由是可达的; VXLAN或UDP数据包到达目的宿主机解封装,解出原始数据包,最终到达目的容器。 Flannel模式如下图所示: 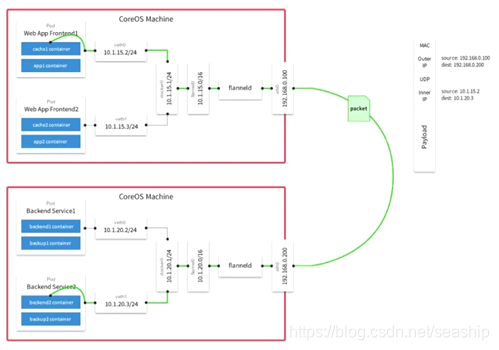 演示: #/opt/bin/etcdctl get /coreos.com/network/config #/opt/bin/etcdctl ls /coreos.com/network/subnets #/opt/bin/etcdctl get /coreos.com/network/subnets/172.16.49.0-24
演示: #/opt/bin/etcdctl get /coreos.com/network/config #/opt/bin/etcdctl ls /coreos.com/network/subnets #/opt/bin/etcdctl get /coreos.com/network/subnets/172.16.49.0-24 转载地址:http://taodi.baihongyu.com/
你可能感兴趣的文章
以太网基础知识
查看>>
慢慢欣赏linux 内核模块引用
查看>>
kprobe学习
查看>>
慢慢欣赏linux phy驱动初始化2
查看>>
慢慢欣赏linux CPU占用率学习
查看>>
2020年终总结
查看>>
Homebrew指令集
查看>>
React Native(一):搭建开发环境、出Hello World
查看>>
React Native(二):属性、状态
查看>>
JSX使用总结
查看>>
React Native(四):布局(使用Flexbox)
查看>>
React Native(七):Android双击Back键退出应用
查看>>
Android自定义apk名称、版本号自增
查看>>
adb command not found
查看>>
Xcode 启动页面禁用和显示
查看>>
【剑指offer】q50:树中结点的最近祖先
查看>>
二叉树的非递归遍历
查看>>
【leetcode】Reorder List (python)
查看>>
【leetcode】Linked List Cycle (python)
查看>>
【leetcode】Linked List Cycle (python)
查看>>